|
Getting your Trinity Audio player ready...
|
Application and functionality of automatic text summarization
This article explains how we combined an ensemble of ML/NLP techniques, including distilled transformers and reinforcement learning via expert feedback. Our prototype is a Responsible AI architecture solution on a Kubernetes cluster that could benefit the banking industry and regulators today.
Application areas of domain-specific automatic text summarization
In a previous BankingHub article our colleagues highlighted the flood of lengthy and complex regulatory publications that require extensive reading and analysis. However, there are other use cases besides regulatory reporting; manual summarization tasks are also prevalent in corporate sales (e.g. for client reporting) and legal departments (e.g. for contracts).
We have investigated the use of emerging technologies such as automatic text summarization to reduce the workload on the human workforce.
How does automatic text summarization work?
Automatic text summarization (ATS) is a subdomain of natural language processing (NLP) that generates a condensed summary of a document. It can take single or multiple documents as input and provide extractive or abstractive summaries (Awajan, 2020) as output for generic query-based or domain-specific purposes (Chauhan, 2018). Extractive summaries select important sentences from the input text, while abstractive summaries require the AI to create coherent phrases on its own, making it more challenging.
We have developed a cloud-native automatic text summarization solution that utilizes a zero-shot[1] learning approach due to the lack of training data. In this article, we will share our experiences with this text summarization application. Our investigation focused on domain-specific topics such as “asset quality”, “credit lending”, “pandemic” and “climate risk”, which were critical areas of attention at that time.
How effective are the NLP models for text summarization?
Transfer learning (Fulgosi, 1976) is a common practice in ML/NLP, where pre-trained language models are used for similar applications instead of building new models from scratch. The latest research in NLP has focused on deep neural networks as large language models (LLM) for transfer learning.
The most promising pre-trained models for text summarization include:
Although large language models are currently on the hype, the size of the model is only one of many factors determining the effectiveness of an NLP model. Other factors also matter, such as quality and size of training data, model architecture, pre-training and fine-tuning, domain specific relevance, model complexity, hyper parameter tuning, evaluation metrics, computational resources and nowadays also ethical considerations.
While larger models like GPT-4 have shown impressive experimental success, smaller models such as Alpaca[7] and various distilled transformers can achieve comparable levels of accuracy. Their smaller size makes the deployment of Alpaca or DistilBERT[8] more convenient, as they can even run on IoT edge devices such as mobile phones or Raspberry Pi.
For the processing of regulatory requirements, we need to perform single-document, domain-specific/query-based, multi-sentence text summarization. Although there are promising existing solutions available on the market, we still encounter several challenges.
What are the challenges when it comes to using pre-trained models?
Long document: Pre-trained models are based on seq2seq encoder-decoder architecture, which practically means that the given text needs to be compressed into a fixed-length vector, resulting in a limit of 512 or 1024 tokens for most of the transformers.[9]
This limits the candidate pre-trained models available for our purpose. Using the pre-trained model based on Bidirectional Encoder Representations from Transformers (BERT) (McCormick, 2020), several state-of-the-art (SOTA) transformers have been experimented such as
- Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models (PEGASUS) (Jingquing Zhang, 2019)
- BART by Meta AI (Facebook), a denoising autoencoder generalizing both BERT and GPT-3
- Text-To-Text-Transfer-Transformer (T5)
Attention: The generic off-the-shelf text summarization solutions do not pay attention to specific topics upfront. The summary is generic, as if done by a human reading a document without attention. However, we would get different summaries based on the same document if we paid attention to a specific topic, such as Covid-19, environment or law. Therefore, we cannot simply use generic pre-trained models if we want our summaries to be topic-specific.
Evaluation metrics: SOTA models use ROUGE[10] and BLEU[11] to evaluate summary quality (Fabbri et al. 2021). The challenge is that ROUGE and BLEU are not differentiable. Hence, they cannot be used as an optimization function for back-propagation-based deep learning neural networks to automatically learn, i.e. adjust the parameters. Therefore, other metrics like RMSE are used for optimization. However, optimizing for RMSE can lead to poor ROUGE and BLEU scores.
How does our text summarization algorithm work in detail?
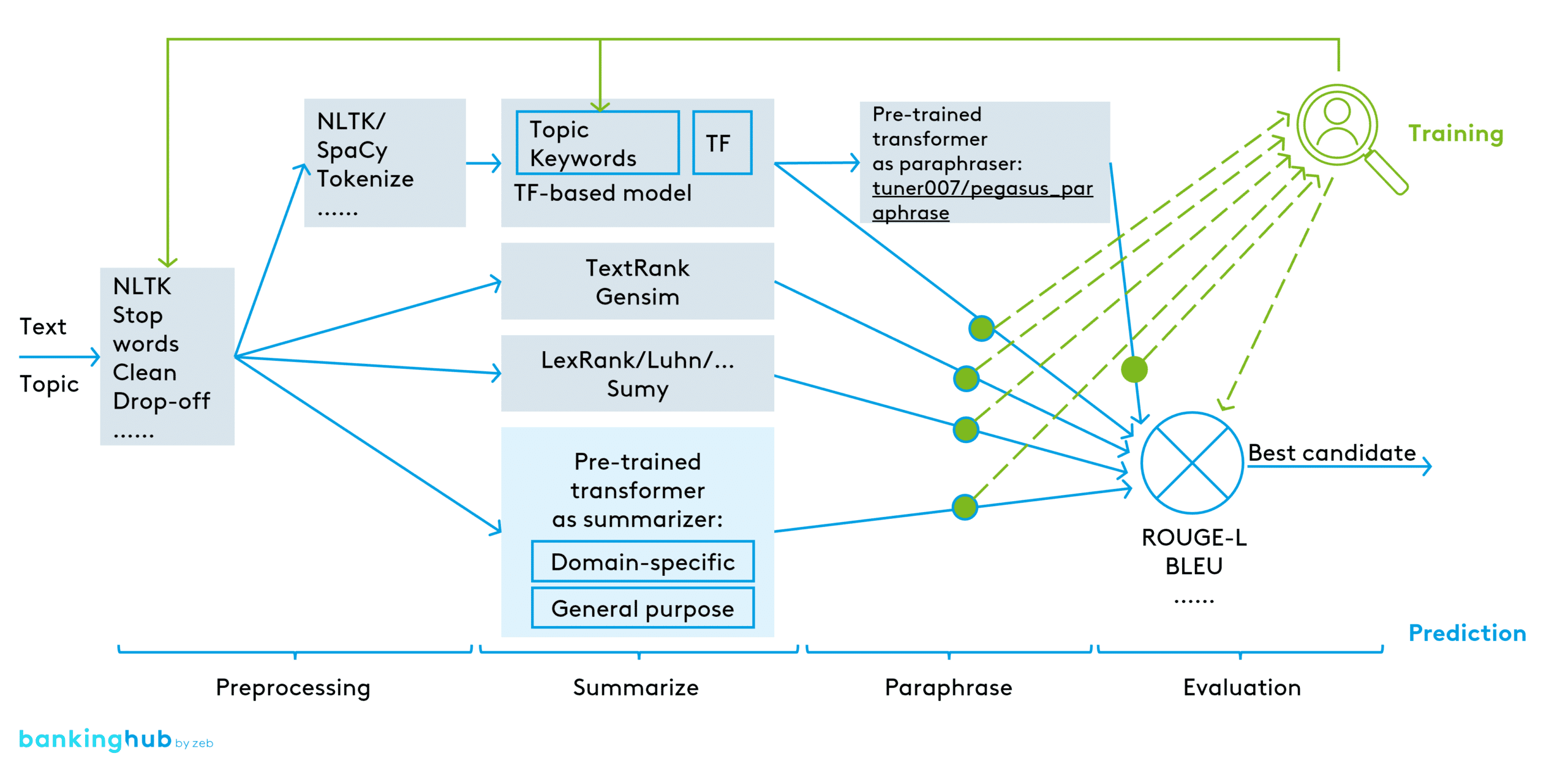
As shown in Figure 1, we use an ensemble architecture to simultaneously run an extractive summarization model based on Term Frequency (TF), TextRank (TR) and LexRank (LR) to get 3 candidate summaries. We take the TF output as input for the Seq2Seq model (Sutskever et. al, 2014). The encoder takes our extractive summary as input and ‘understands’ it in vectors. The decoder generates coherent and semantically equivalent paraphrases as final output.
Based on the evaluation metric using ROUGE-L[12] and BLEU, we select the best out of all the models.
- The extractive methods (TF, TR, LR) have the advantage of generating the summary faster without limitation on input size. However, the summary is created by simply selecting the most important sentences from the document.
- Abstract methods (Seq2Seq) are more advanced, taking a pre-trained neural network to “understand” the document and create new sentences based on it. However, they suffer from the challenges we mentioned before for pre-trained models.
Our architecture takes the advantages from both approaches and compensates their drawbacks.
As paraphraser (at the top right of Figure 1), we selected the pre-trained model dedicated for paragraphing based on the best performant PEGASUS model.
- “tuner007/pegasus_paraphrase”
As candidate summarizers (at the bottom of Figure 1), we’ve tried out different transformers (pre-trained models) from the platform huggingface[13].
For topics such as “asset quality” and “credit lending”, the domain-specific transformers
- “human-centered-summarization/financial-summarization-pegasus”
- “nsi319/legal-pegasus”
have been used because they were trained on specific finance and law data.
For the rest, e.g. “pandemic” and “climate risk”, general purpose transformers
- “google/pegasus-xsum”
- “facebook/bart-large-cnn”
have been used because they have been trained on generic news.
In our experiments, GPT-2 and T5 could not handle large documents, while BigBirdPegasus generated summaries with repeated sentences, making them unsuitable for abstractive summarization. Hence, we did not use them.
We collaborated with regulatory reporting experts to evaluate the generated summaries and optimize the pre-processing keywords and algorithm parameters based on their feedback through model engineering, which is a form of “reinforced learning” with expert input.
For future experiments, hierarchical summarization can be used as an alternative technique, where the input document is divided into smaller sub-documents and a summary is generated for each sub-document, which is then combined to create a final summary.
Another future approach is to fine-tune more recent existing LLM models on a dataset of large documents to improve their performance. For example, we could fine-tune the open-source LLM GPT-J and integrate via dedicated pipelines, e.g. Python LangChain[14], an anonymization filtering engine, such as Presidio[15] to find out the emergent moment of local LLMs on our specific protected data.
What have we achieved with our text summarization algorithm?
We overcame the challenges by combining heuristics to create a solution with multiple advantages.
- Our approach can handle long documents, even more than 100,000 token. SOTA transformers, in comparison, are mainly limited to 1024 token. GPT-3 is limited to 2048,
- Our above solution architecture allows the generation of summaries for large documents within seconds, unlike other SOTA solutions like GPT-3 that take several minutes.
- We used a zero-shot training approach based on pre-trained transformers, in contrast to SOTA solutions that require enormous amounts of training data and at least one shot in case of GPT-3.
- We also used the same metrics (ROUGE and BLEU) for both optimization and evaluation, and our results achieved ROUGE scores of over 50%, which is competitive to SOTA scores[16].
In this article, we have shown a possible way to build industry-specific and economic solutions for text summarization in the financial services sector, independent of large public language models such as GPT. Financial services institutions should keep a close eye on the rapid development to leverage efficiency potentials.







